بررسی تفاوت مفاهیم پایگاه داده، انبار داده، دریاچه داده و بازار داده

آنچه در این مقاله میخوانید
ذخیرهسازی و مدیریت اطلاعات در جوامع امروز، از اهمیت بالایی برخوردار است و این امر سبب شده تا فناوریهای متنوع و بسیاری برای پیادهسازی آن ایجاد شود که هریک دارای ویژگیها و مزایای خاص خود هستند. پایگاه داده، انبار داده، دریاچه داده و بازار داده از جمله مفاهیمی هستند که این روزها در علم داده بسیار مورد استفاده قرار میگیرند. در این مقاله تلاش شده است تا شما با مفاهیم ابتدایی این واژهها آشنا شده و تفاوتهای آنها را به خوبی تشخیص دهید.
پایگاه داده چیست؟
پایگاه داده مجموعهای از دادههای یک بخش خاص از کسبوکار شما است که این دادهها را در زمان واقعی (real-Time) ذخیره میکند: وظیفه اصلی آن پردازش تراکنشهای روزانه شرکت شما مانند ثبت موارد فروخته شده است. پایگاههای داده برای پاسخگویی به نیازهای اطلاعاتی یک سازمان طراحی شده و توسط یک سیستم مدیریت پایگاه داده قابل دسترسی هستند.
انبار داده چیست؟
انبار داده در واقع مجموعه بزرگی از دادههای تجاری است که بعد از انجام یک سری عملیات، به سازمان کمک میکند تا تصمیمهای مؤثری برای ارتقای خود در زمینههای مختلف بگیرد.
بخش زیادی از اطلاعاتی که در انبارهای داده وجود دارد از عوامل مختلفی در برنامههای داخلی مانند بازاریابی، فروش و امور مالی، برنامههای مشتری مداری و سیستمهای شرکای خارجی تامین میشوند.
در سطح فنی، یک انبار داده به طور منظم اطلاعات را از چنین برنامهها و سیستمهایی بیرون میکشد. سپس دادهها، فرآیندهای سازماندهی و انتقال اطلاعات را برای مطابقت با دادههای موجود در انبار طی میکنند. انبار داده این اطلاعات پردازششده را ذخیره میکند تا آماده دسترسی توسط افراد باشد. اینکه اطلاعات چند وقت یک بار استخراج یا سازماندهی شوند به نیاز سازمان بستگی دارد و متفاوت خواهد بود.
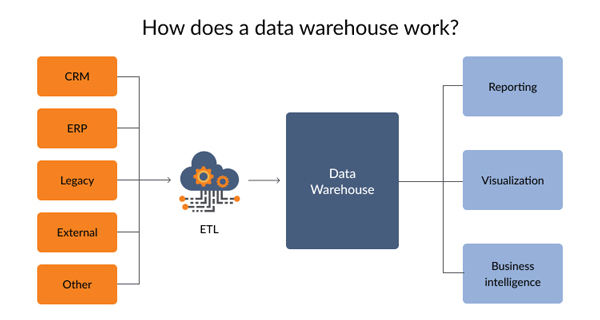
ETL چیست؟
ETL فرآیند جمعآوری داده از منابع دادهای مختلف، سازماندهی آنها در کنار یکدیگر و بارگذاری در یک انبار داده واحد تشکیل می گردد.
در بسیاری از شرکتها حجم زیادی از دادههای مهم غیر قابل دسترس و در نتیجه بدون استفاده هستند. نتایج تحقیقات نشان میدهد، دو سوم کسب وکارها یا به ندرت از دادهها استفاده میکنند یا هیچ استفادهای نمیکنند. تحقیقات دیگری نشان میدهد که ۵۰ درصد مدیران اعتقاد دارند که سازمان آنها بر اساس داده و تحلیل رقابت نمیکند، که دلیل عمده آن دادههای بدون استفاده در سیستمهای قدیمی و بلااستفاده است.
ETL در واقع به جریان انداختن این دادهها با استخراج داده از منابع دادهای مختلف در سازمان یا خارج از آن، پاکسازی و تبدیل به شکل موردنیاز و نهایتاً ایجاد ساختار مناسب برای پیادهسازی هوش تجاری است. ETL معمولاً یک فرآیند تکراری و خودکار است که به صورت روزانه، هفتگی یا ماهانه تکرار میشود.
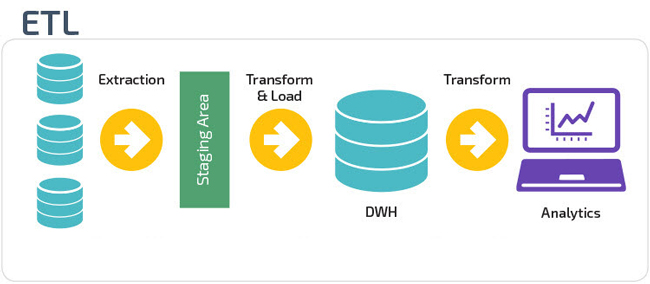
فرایند ETL
فرایند ETL دارای ۳ مرحله Extraction، Transform و Load است.
قدم اول: Extraction
در این مرحله دادهها از منابع مختلف استخراج میشوند و در Staging Area ذخیره میشوند. با این عمل عملکرد منابع اصلی داده حین تبدیلات تحتتأثیر قرار نمیگیرد. همچنین اطلاعات مخدوش و نامناسب مستقیماً به انبار داده منتقل نمیشود. در واقع این مرحله این فرصت را در اختیار ما قرار میدهد که دادهها را اعتبارسنجی کرده و از صحت دادهها اطمینان حاصل کنیم. دادههای استخراج شده از منابع مختلف باید در یک انبار داده یکپارچه شوند.
دادهها از منابع مختلف مثل csv، اکسل، اکسس، اوراکل، SQL Server، صفحات وب، سیستمهای قدیمی سازمان، CRM، ERP و همچنین اطلاعات فروشندهها یا شرکای تجاری و بسیاری از منابع دادهای دیگر در یک انبار داده واحد گردآوری میشوند. در واقع قبل از استخراج و بارگذاری داده به صورت فیزیکی یک نقشه منطقی (Logical Data Map) به منظور توصیف روابط بین دادهها و منابع مختلف دادهای و مقصد آن ها مورد نیاز است.
در این مرحله دادههای غیرضروری حذف و تکرارها نیز شناسایی و حذف میشوند. همچنین نوع دیتا (Data Type) مورد بررسی و اصلاح قرار میگیرد.
قدم دوم: Transformation
دادههای استخراجشده از منابع داده به صورت خام هستند و معمولاً آماده استفاده و تحلیل نیستند. دادههای خام در این مرحله باید پاکسازی و به فرمت مورد نیاز تبدیل شوند. در واقع این مرحله کلید فرآیند ETL است که طی آن داده خام به داده ارزشمند و قابل استفاده به منظور تحلیل و ساخت گزارشهای تحلیلی و پیادهسازی هوش تجاری در سازمان تبدیل میشوند.
در این مرحله بسیاری از تبدیلات و محاسبات صورت میپذیرد. به طور مثال ممکن است محاسبه سن کاربران در پایگاه داده انجام نشده باشد. یا محاسبه تعداد فروش ضرب در قیمت کالا برای هر سفارش محاسبه نشده باشد. همچنین ممکن است نام و نام خانوادگی در پایگاه داده در ستونهای جداگانه ذخیره شده باشد که در این مرحله میتوان یک ستون به منظور ایجاد نام و نام خانوادگی ایجاد کرد. در واقع میتوان این محاسبات را در این مرحله انجام و از موکول کردن آن به مرحله تحلیل جلوگیری کرد.
در این مرحله ممکن است دادههای یکسانی به علت اشتباه کاربر با نگارش متفاوت درج شده باشد. ممکن است از نگارشهای مختلف یک مقدار برای ذخیره در پایگاه داده استفاده شده باشد (مثل طهران و تهران)، همچنین ممکن است دادههای یکسانی با نامهای متفاوت در پایگاه داده (به طور مثال درج مدرک لیسانس و کارشناسی یا فوق لیسانس و کارشناسی ارشد برای کاربران مختلف) درج شده باشد که باید استاندارد و یکسانسازی شوند.
در دنیای واقعی بسیار پیش میآید که به طور مثال اپلیکیشنهای متفاوت عددهای متفاوتی را برای کد مشتری ایجاد میکنند. این کدها برای ارتباط با یکدیگر باید یکسانسازی شوند.
ممکن است دادهها دارای مقادیر خالی (Blank) باشند یا برای برخی از دادهها مقادیر غیرمنطقی درج شده باشد (به طور مثال عدد ۷ رقمی برای کد ملی مشتری) که در این صورت میتوان برای مدیریت آنها تدابیری اندیشید.
در این مرحله باید ستونهای موردنیاز برای بارگذاری مشخص شوند. در واقع باید از بارگذاری ستونهای غیرلازم مانند شماره تلفن، ایمیل و ویژگیهایی که تاثیری در تحلیل ندارند پرهیز نمود.
در مرحله Transformation باید از قوانین و جداول کمکی (Lookup Tables) جهت استانداردسازی مقادیر بهره گرفت. همچنین در این مرحله تبدیل واحدها به یکدیگر صورت میپذیرد. به طور مثال ممکن است در جایی فروش به صورت دلاری ذخیره شده باشد و در جای دیگر به صورت ریالی که باید در این مرحله استانداردسازی صورت پذیرد.
همچنین بررسی صحت و اعتبارسنجی دادهها در این مرحله نیز صورت میپذیرد. به طور مثال سن نباید بیشتر از ۲ عدد باشد یا کد ملی نمیتواند کمتر یا بیشتر از ۱۰ رقم باشد.
اگر نیاز به ادغام ستونها یا جداسازی ستونها و تبدیل آنها به چندین ستون باشد، در این مرحله انجام میگیرد.
قدم سوم: Loading
بارگذاری داده در انبار داده آخرین قدم در فرآیند ETL است. معمولا حجم زیادی از داده باید در یک مدت زمان کوتاه در انبار داده بارگذاری شوند لذا توجه به بهینهسازی عملکرد (Performance) بسیار ضروری به نظر میرسد.
همچنین ممکن است فرآیند بارگذاری داده در حین اجرا با شکست مواجه شده و متوقف شود. عمل ریکاوری باید دقیقاً از نقطه توقف صورت پذیرد و اعمال لازم جهت جلوگیری از عدم یکپارچگی و تکرار یا از بین رفتن دادهها صورت پذیرد.
تفاوت انبار داده با پایگاه داده
طبیعی است اگر انبار داده را با پایگاه داده اشتباه بگیرید، زیرا هر دو دارای مفاهیم مشابهی هستند. با این وجود، تفاوت اصلی هنگامی مشخص میشود که یک کسبوکار نیاز به تجزیه و تحلیل روی مجموعه بزرگی از دادهها داشته باشد. انبارهای داده برای انجام این نوع کارها ساخته میشوند. در حالی که در مورد پایگاه داده اینطور نیست. در اینجا این دو را با هم مقایسه میکنیم و تفاوت آنها را به شما نشان میدهیم:
انواع پردازش: OLAP و OLTP
مهمترین تفاوت پایگاه داده و انبار داده نحوه پردازش دادهها است. پایگاههای داده از سیستم پردازش تراکنشی آنلاین (OLTP) برای حذف، درج، جایگزینی و بهروزرسانی سریع تعداد زیادی از تراکنشهای کوتاه آنلاین استفاده میکنند. این نوع پردازش بلافاصله به درخواستهای کاربر پاسخ میدهد و بنابراین برای پردازش عملیات روزانه یک کسب و کار در زمان واقعی استفاده میشود. به عنوان مثال اگر کاربری بخواهد با استفاده از فرم رزرو آنلاین اتاق هتلی را رزرو کند مراحل کار با OLTP انجام میشود.
انبارهای داده از سیستم پردازش تحلیلی آنلاین (OLAP) برای تجزیه و تحلیل سریع حجم عظیمی از دادهها استفاده میکنند. این فرایند به تحلیلگران امکان میدهد تا از طریق دیدگاههای مختلف به دادههای شما نگاه کنند. به عنوان مثال با این که پایگاه داده شما دادههای فروش را برای هر دقیقه در هر روز ثبت میکند شاید شما فقط بخواهید از کل مبلغ فروخته شده به صورت روزانه مطلع شوید. برای انجام این کار باید دادههای فروش را هر روز جمع آوری کرده و خلاصه کنید. OLAP به طور خاص این وظیفه را برعهده دارد. از این سیستم برای انبار کردن دادهها استفاده میشود که حدود ۱۰۰۰ برابر سریعتر از OLTP برای انجام همان محاسبه طراحی شده است.
دریاچه داده چیست؟
مانند حالتی که چندین رودخانه از منابع متفاوت و با اجزای مختلف وارد یک دریاچه واحد میشوند، دریاچه داده نیز نوعی مخزن ذخیرهسازی مرکزی است که کلان داده ها را از منابع مختلف در فرمت خام و دست نخورده ذخیره می کند. Data Lake قادر است دادههای ساختاریافته، نیمه ساختاریافته، یا بدون ساختار را ذخیره کند.
داده های ذخیره شده در دریاچه داده دارای شناسهها (Tag)، فرادادهها و برچسبها و هر اطلاعات اضافی دیگری هستند که برای بازیابی آسان باشند. انواع مختلفی از تجزیه و تحلیل را میتوان در مورد آنها اعمال کرد. از هوش مصنوعی (AI) گرفته تا پردازش دادههای بزرگ (Big Data)، تجزیه و تحلیل Real-time و یادگیری ماشین (Machine learning) و هر عملیات دیگری که برای کمک به تصمیمگیری بهتر و ارزشآفرینی منجر شود.
تفاوت دریاچه داده و انبار داده
دریاچه داده و انبار داده یک هدف پایهای و اساسی دارند و این باعث میشود تا افراد آنها را با هم اشتباه بگیرند:
- هر دو مخزن ذخیرهسازی هستند که دیتااستورهای مختلف را در یک سازمان ادغام میکنند.
- هدف هر دوی آنها ایجاد یک دیتااستور (data store) است که خدمات مختلف را یکجا ارائه میکند و اطلاعات را روی اپلیکیشنهای مختلف قرار میدهد.
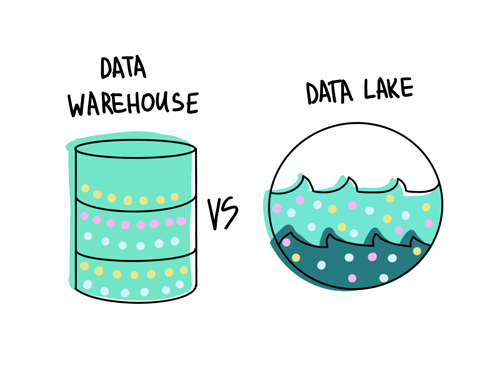
با این حال، تفاوتهای اساسی بین Data Lake و انبار داده وجود دارد که باعث میشود تا آنها برای فرآیندهای متفاوتی استفاده شوند:
- خواندن با ساختار و نوشتن با ساختار (Schema-on-read vs schema-on write): طرح یا اسکیمای یک انبار داده قبل از ذخیره سازی تعریف و ساختار یافته میشود (طرح و اسکیما هنگام نوشتن دادهها اعمال میشود). در مقابل، یک دریاچه داده هیچ طرح و برنامهی از پیش تعیین شدهای ندارد تا به آن اجازه دهد که دادهها را در فرمت اصلی خود ذخیره کند. بنابراین، در انبار داده اکثراً آماده سازی دادهها به طور معمول قبل از پردازش اتفاق میافتد ولی در Data Lakes هنگامی که دادهها واقعاً مورد استفاده قرار بگیرند، آماده سازی میشوند.
- دسترسی کاربری ساده و پیچیده: از آنجا که دادهها قبل از ذخیره سازی به شکل ساده شده سازماندهی نشدند، یک دریاچه داده اغلب نیاز به یک متخصص با درک کامل انواع مختلف دادهها و روابط آنها دارد تا بتواند آنها را بخواند. در عوض یک انبار داده به دلیل طرح و اسکیمای مستند خود و به دلیل این که به خوبی تعریف شده، هم برای کاربران فناوری و حتی افرادی با تخصص کمتر نیز قابل دسترسی است. حتی یک عضو جدید در تیم میتواند به سرعت از انبار داده استفاده کند.
- انعطاف پذیری و غیر قابل تغییر بودن: در انبار دادهها نه تنها تعریف طرح یا schema زمان میبرد، بلکه در صورت تغییر موارد مورد نیاز منابع زیادی باید اصلاح و بهبود یابد. با این حال، دریاچههای داده میتوانند به راحتی با تغییرات سازگار شوند. همچنین، با افزایش نیاز به ظرفیت ذخیره سازی، مقیاس گذاری سرورها در یک مجموعه دریاچه داده آسانتر میشود.
بازار داده
بازار داده (Data mart) نوعی انبار داده است که در جهت رفع نیازهای یک تیم خاص یا واحد کسبوکار مشخص مانند بخش مالی، بازاریابی یا فروش ایجاد شده است. بازار داده، کوچکتر و متمرکز است و ممکن است شامل خلاصهای از دادههایی باشد که به بهترین وجه نیازهای کاربران خود را رفع میکند.
ساخت یک بازار داده (Data Mart) به مراتب سادهتر و کمهزینهتر از ساخت یک انبار داده است و در زمان نیز صرفهجویی میشود. بسیاری از سازمانها یا شرکتهای بزرگ که به واحدهای کوچکتر تقسیمبندی میشوند، میتوانند از بازار داده به جای انبار داده برای طراحی خود استفاده کنند.
انواع بازارهای داده
در کل سه نوع مختلف بازار داده (Data Mart) وجود دارد. وابسته (Dependent)، مستقل (Independent) و ترکیبی (Hybrid). بازار داده وابسته (Dependent Data Mart) به بازار دادهای میگویند که از روی یک انبار داده ساخته میشود. یعنی ابتدا انبار داده را میسازیم و سپس یک زیر مجموعه مشخص از آن را استخراج میکنیم. برعکس آن بازار داده مستقل (Independent Data Mart) است که میتواند بدون دخالت انبار داده، دادهها را از منابع داده استخراج کرده و ذخیره کند. حالت ترکیبی هم حالتی است که هم از انبار داده استفاده میکند و هم به صورت مستقیم از منابع داده، بازار داده را میسازد.
تفاوت انبار داده با بازار داده
انبارهای داده نیز گاهی با بازار داده اشتباه گرفته میشوند. اما انبارهای داده عموماً بسیار بزرگتر بوده و شامل اطلاعات متنوعی هستند، در حالی که بازار داده عملکرد محدودتری را در اختیار دارد.
بازار داده اغلب زیرمجموعههای یک انبار داده است که برای انتقال آسان دادههای خاص به یک کاربر خاص و برای یک برنامه مشخص طراحی میشود. به زبان ساده تر، بازار داده را میتوان یک موضوع واحد در نظر گرفت، در حالی که انبارهای داده چندین موضوع را تحت پوشش قرار میدهند.
یک پیشنهاد!
در صورت تمایل می توانید اطلاعات جامعی در رابطه با سامانه های هوش تجاری و داشبورد های مدیریتی شرکت سبزافزار آریا کسب کنید.
آشنایی با ویژگی های سامانه هوش تجاری
درسنامه
- ۱
مفاهیم هوش تجاری و راهنمای بکارگیری آن در صنعت خرده فروشی
- ۲
۱۵ داشبورد مدیریتی پر کاربرد در صنعت خرده فروشی که هر مدیر فروشگاهی به آن نیاز دارد
- ۳
مهم ترین کاربردهای داده کاوی در صنعت خرده فروشی
- ۴
یادگیری ماشین چیست و در خردهفروشیها چه کاربردی دارد؟
- ۵
بررسی تفاوت مفاهیم پایگاه داده، انبار داده، دریاچه داده و بازار داده
- ۶
تحلیل پیشرفته کسبوکار یا Business Analytics در خرده فروشی چه کاربردی دارد؟
- ۷
معرفی نرمافزار Power BI
- ۸
هوش تجاری و رشد فروش
- ۹
آیا AI آینده خرده فروشی خواهد بود؟